데이터 요약의 extraction 방법 중 하나인 텍스트랭크(TextRank) 알고리즘을 보도록 하겠습니다.
2004년 Rada Mihalcea와 Paul Tarau의 TextRank: Bringing Order into Texts 논문에서 텍스트 처리를 위한 그래프 기반 랭킹 모델(graph-based ranking model)인 TextRank를 소개했습니다.
graph-based ranking 알고리즘은 각 정점의 정보만을 고려하지 않고 전체 그래프의 글로벌 정보를 재귀적으로 계산하여 정점의 중요도를 결정하는 방법입니다.
텍스트랭크 알고리즘은 키워드(keyword) 추출과 문장(sentence) 추출 방법을 제공합니다.
그래프 기반 모델이기에 그래프 관련 용어가 나옵니다. 간단하게 보고 넘어가겠습니다.
그래프는 유한하며 공집합이 아닌 정점 집합 \( V\)와 엣지 집합 \( E\)를 정의합니다.
A graph is a finite, the vertex set \(V \), the edge set \(E\), \( (V, E \not= \emptyset )\).
Directed Graph
\( G = (V, E)\) be a directed graph with the \(V\) and \(E\), where \( E \subset V \times V \). \((a,b \in V, a\not=b). \)
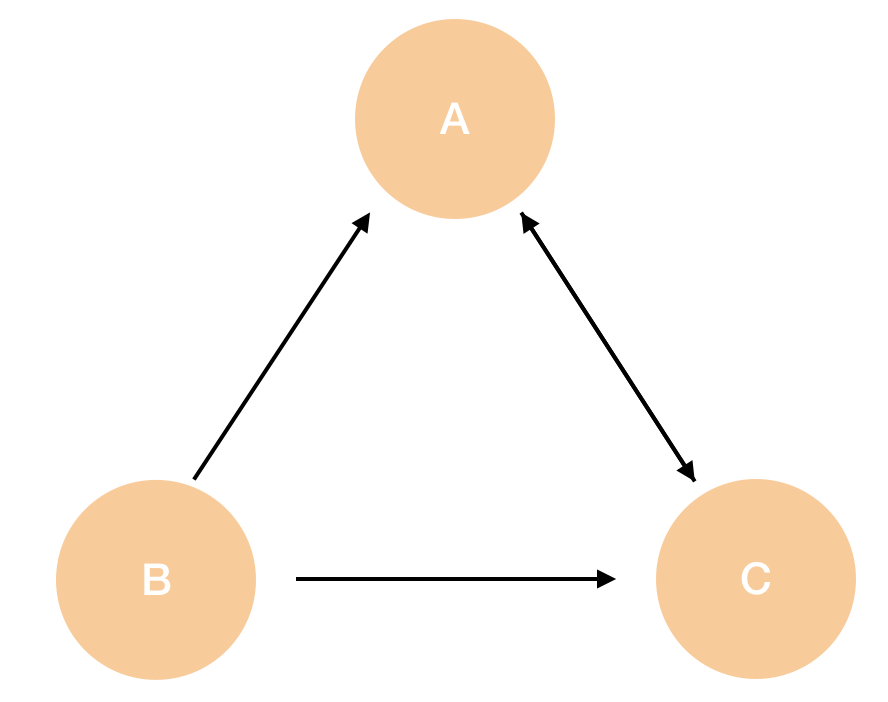

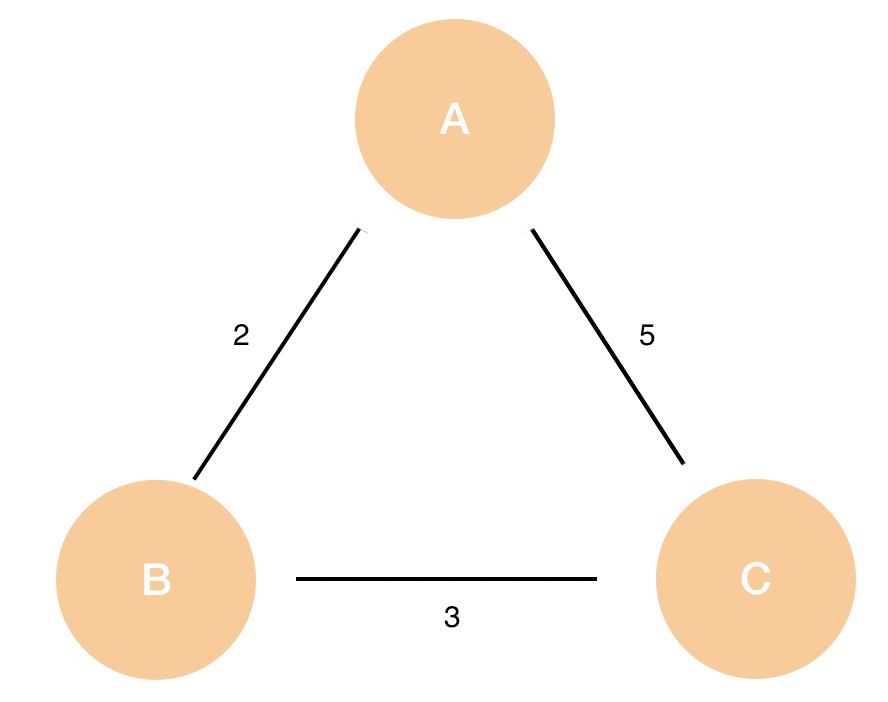
페이지랭크 알고리즘은 unweighted 그래프를 기반으로 정의하지만 텍스트랭크 알고리즘은 자연어 텍스트로 만들어지기에 weigheted 그래프를 기반으로 합니다. 따라서 두 정점 \( v_i \)와 \( v_j \) 사이의 가중치(weight) \( w_{ij} \)를 더하여 "strength"를 나타내는 방식으로 모델을 고려합니다.
논문에서 새로운 공식을 제시합니다.
- \(V\) : 정점(vertex)
- \(E\) : 엣지(edge)
- \(G=(V, E) \) : directed graph
- \(In(V_i) \) : 점을 가리키고 있는 정점 집합(predecessor)
- \(Out(V_i) \) : 점이 가리키는 정점 집합(successor)
- \( d \) : damping factor (0과 1사이의 값, 0.85 사용)
$$WS(V_i) = (1-d) + d\sum_{V_j \in {In(V_{i})}} \frac{w_{ji}}{\sum_{V_k\in{Out}(V_j)} w_{jk}} WS(V_j). $$
(\(WS\)는 Weighted Sum의 약자입니다.) 이 부분 또한 수정되지 않은 페이지랭크 알고리즘 수식을 사용했습니다. 하지만 대부분 1-d를 사용하는 것으로 보입니다. 나중에 돌아와 봅시다. (이와 관련해서 지난 페이지랭크 알고리즘 글을 보시길 바랍니다.)
텍스트를 어휘(lexical)나 의미(semantic)로 그래프를 만들 수 있습니다. 자연어 텍스트에 대해 그래프 기반 순위 알고리즘은 다음과 같이 동작합니다.
1. Identify text units that best define the task at hand, and add them as vertices in the graph.
2. Identify relations that connect such text units, and use these relations to draw edges between vertices in the graph. Edges can be directed or undirected, weighted or unweighted.
3. Iterate the graph-based ranking algorithm until convergence.
4. Sort vertices based on their final score. Use the values attached to each vertex for ranking/selection decisions.1. 텍스트를 식별하고 점으로 추가합니다.
2. 텍스트 간 관계를 식별하고 엣지를 그립니다. directed, undirected, weighted, unweighted 가 될 수 있습니다.
3. 수렴할 때까지 그래프 기반 랭킹 알고리즘을 반복합니다.
4. 점수에 따라 점들을 정렬합니다.
이를 바탕으로 키워드 추출과 문장 추출을 보겠습니다.
키워드 추출 (Keyword Extraction)
키워드 추출은 문서를 잘 설명하는 단어를 텍스트에서 식별하는 것입니다. 쉬운 방법으로 빈도를 사용하여 텍스트 내에 중요한 단어를 판단하는 것을 생각할 수 있습니다. 하지만 당시 논문에서는 이 결과가 좋지 않다고 하네요.
텍스트랭크(Textrank) 방식의 키워드 추출 방법을 보겠습니다. 예상되는 결과는 앞서 소개한 내용처럼 텍스트를 대표하는 단어(word) 또는 구문(phase)이 되겠습니다. 두 단어 사이에 co-occurrence 관계를 사용합니다. co-occurrence 관계는 N 범위를 기준으로 연결되는 단어의 수를 의미합니다. 두 단어의 간격이 최대 범위 \(N\) 사이에서 연결되며 \(N\)은 2~10 사이의 값입니다.
two vertices are connected if their corresponding lexical units co-occur within a window of maximum N words, where N can be set anywhere from 2 to 10 words.
말로 표현하니 제대로 전달이 되지 않는것 같습니다. 예를 들어 보도록 하겠습니다. 다음 text 문장을 Window size=2(여기서는 \(N\)=2)를 사용하여 co-occurrence를 구해봅시다.
text = ["Mon Tue Sat Wed Sat Thu Fri Fri Sat Sun"].
먼저 Wed를 기준으로 보겠습니다.
Mon Tue Sat Wed Sat Thu Fri Fri Sat Sun
\(N\)=2 이므로 양옆의 2개 단어를 확인합니다. Wed는 총 Sat 2회, Thu 1회, Tue 1회 연결되었습니다.
여러 번 등장하는 Sat를 기준으로 보겠습니다.
Mon Tue Sat Wed Sat Thu Fri Fri Sat Sun => Mon 1회, Tue 1회, Wed 1회, Sat 1회
Mon Tue Sat Wed Sat Thu Fri Fri Sat Sun => Thu 1회, Fri 1회, Wed 1회, Sat 1회(중복)
Mon Tue Sat Wed Sat Thu Fri Fri Sat Sun => Fri 2회, Sun 1회
Sat는 총 Mon 1회, Tue 1회, Wed 2회, Thu 1회, Fri 3회, Sat 1회, Sun 1회입니다. 서로를 가리키는 중복은 제외합니다. 이를 반복하여 다음과 같은 결과를 얻을 수 있습니다.
Fri Mon Sat Sun Thu Tue Wed
Fri 1 0 3 1 2 0 0
Mon 0 0 1 0 0 1 0
Sat 3 1 1 1 1 1 2
Sun 1 0 1 0 0 0 0
Thu 2 0 1 0 0 0 1
Tue 0 1 1 0 0 0 1
Wed 0 0 2 0 1 1 0co-occurrence 관계가 이해가 되셨길 바랍니다.
다시 논문을 보겠습니다.

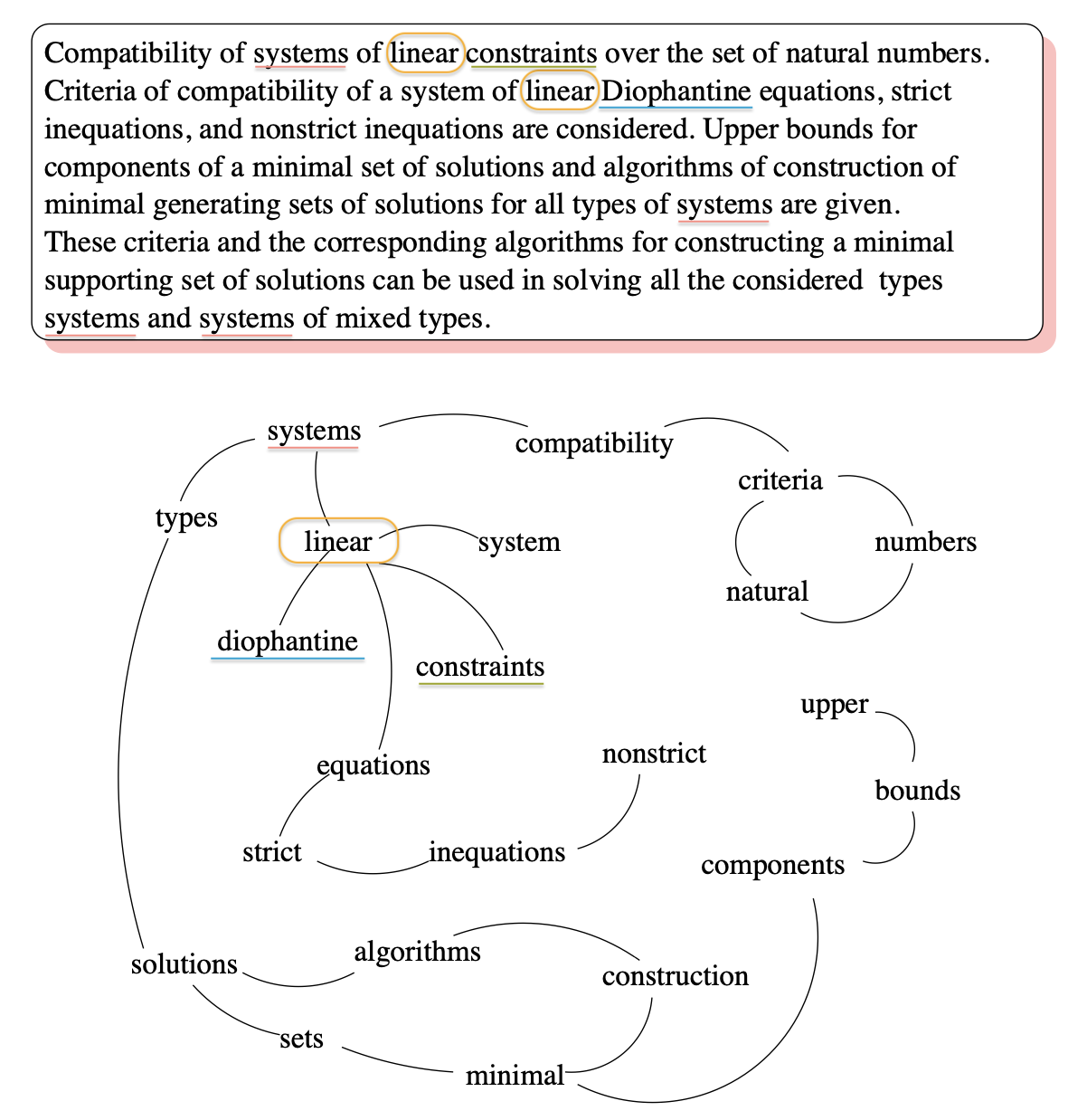
그림과 같이 연결된 단어를 기준으로 그래프가 그려지는 것을 확인할 수 있습니다.
그래프에 추가된 정점은 특정 어휘(lexical)만 선택할 수 있는 필터를 사용할 수 있습니다. 예를 들어, 명사와 동사를 기준으로 정점을 나눌 수 있습니다. 나중에 동사와 명사 사이에 연결할 수 있는 관계가 있으면 edge를 연결할 수 있습니다.
먼저 텍스트를 토큰화(tokenized)합니다. 필터 적용을 위한 사전 처리 단계입니다. 단일 단어(single words)만을 고려하며 다중 단어(multi-word)는 후처리 단계에서 재구성됩니다.
다음으로 필터를 통과한 단어가 추가되고 범위 내에 엣지를 추가합니다. 각 정점은 초기값 1을 가집니다. 이 알고리즘이 수렴될 때까지 여러 번 반복됩니다. 정점은 점수의 역순으로 정렬되고 상위 T 개의 정점은 후처리를 위해 유지됩니다. T는 고정값으로 설정할 수 있으며 일반적으로 5~20개의 키워드 범위입니다.
문장 추출 (Sentence Extraction)
문장 추출은 키워드 추출과 유사합니다. 텍스트랭크를 적용하기 위해서 먼저 그래프를 생성합니다. 문장 추출의 경우 전체 문장에 대해 점수를 매기는 것입니다. 따라서 각 문장에 대해 정점이 추가됩니다.
키워드 추출에서 사용한 co-occurrence 관계는 문장 추출에서 사용할 수 없습니다. 따라서 다른 관계를 설정합니다. 두 문장에 공통으로 포함되는 단어의 개수를 각 문장의 단어 개수의 log 값의 합으로 나눈 값입니다. 수식으로 표현하면 다음과 같습니다.
문장 \(S_i\)는 \( N_i \)개의 단어로 표현됩니다. \( S_i = w_1^i, w_2^i, \ldots, w_{N_i}^i \). 두 문장 \( S_i \)와 \( S_j\)에 대해서 문장 유사도는 다음과 같이 계산됩니다.
$$ Similarity( S_i, S_j) = \frac{|\{ w_k | w_k \in S_1\ \And \ w_k \in S_j \} |}{\log(| S_i |) + \log(|S_j|) }. $$
예를 들어 \(S_1 \)과 \(S_2\)가 5, 17 단어로 구성되며 3개의 단어를 공통으로 포함한다고 하겠습니다. \( 3/ (\log(3) +\log(17)) \simeq 0.76 \)으로 계산됩니다. 만일 \(S_1 \)가 16 단어로 구성되면 \( 3/ (\log(16) +\log(17)) \simeq 0.53 \)입니다. (로그의 밑을 자연로그로 계산했습니다. 정확하지 않습니다.)
텍스트랭크 알고리즘을 한 번 다뤄보았습니다.
참고 자료
'개발 > 문서 요약' 카테고리의 다른 글
| TF-IDF(Term Frequency - Inverse Document Frequency) (0) | 2021.01.11 |
|---|---|
| 페이지랭크 알고리즘 (PageRank algorithm) (0) | 2020.12.11 |
| pytube 설치 (0) | 2020.12.02 |
